1.特征选择的概述
1.1 特征工程的简介 相信每一个数据人都深刻地体会过这样一句话:“特征工程做不好,调参调到老”。业界更有这样的说法:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。由此可见,特征工程在机器学习中占有相当重要的地位。到底什么是特征工程,我认为并没有确切的定义,个人是这样理解的:特征工程是利用业务领域和数据科学领域的相关知识,创建使机器学习算法达到最优的特征的过程。特征工程主要包括特征抽取和特征选择两部分。特征抽取主要是依据相关领域知识提取特征,更多的依靠业务知识。下文将重点介绍特征选择。
1.2 特征选择的简介 (1) 什么是特征选择
特征选择 ( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ) ,或属性选择( Attribute Selection ) ,是指从全部特征中选取一个特征子集,使构造出来的模型更好。
(2) 为什么要做特征选择
在机器学习的实际应用中,特征数量往往较多,其中可能存在不相关的特征,特征之间也可能存在相互依赖,容易导致如下的后果:
特征个数越多,分析特征、训练模型所需的时间就越长。
特征个数越多,容易引起“维度灾难”,模型也会越复杂,其推广能力会下降。
特征选择能剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。
选取出真正相关的特征简化了模型,使研究人员易于理解数据产生的过程。
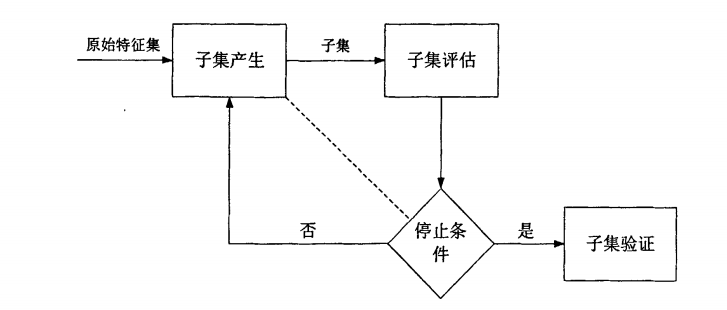
1.3 特征选择的过程 Dash和Liu提出了一个特征选择的基本框架,认为一个典型的特征选择
(1)子集产生:按照一定的搜索策略产生候选特征子集。
(2)子集评估:通过某个评价函数评估特征子集的优劣。
(3)停止条件:决定特征选择算法什么时候停止。
(4)子集验证:用于验证最终所选的特征子集的有效性。
这四个步骤组成了一个完整的特征选择过程。
子集产生是一个搜索过程, 用来产生待评价的特征子集。搜索过程的起始点可以是:不含任何特征的空集;含所有特征的全部特征集;随机的一个特征子集。前面两种情况,特征是迭代地添加或移除。
子集评估过程用于评价特征子集的优劣,即根据某个评价函数对子集进行评价,每进行一次特征子集的优劣评价,将新的评价值和之前保存的最优评价值进行比较,如果新的子集的评价值更优,则用它来取代之前的最优评价值。
子集评估之后要进行停止条件的判断,如果没有停止条件,搜索过程将无法停止。如图所示,子集产生和子集评估都可能影响到停止条件的选择,基于子集产生的停止条件有:a.达到预先指定的特征数目。b.达到预先给定的迭代次数。基于子集评估的停止条件有:a.增加或减少特征不能使特征子集的评价值有所提高。b.使评价函数取最优解的特征子集已经找到。
子集有效性验证是特征选择的最后一个步骤,在实际应用中是必不可少的,有效性验证通常用经过特征选择算法处理后的数据集进行训练和预测,将训练和预测的结果和在原始数据集上的结果进行比较,比较的内容包括预测的准确性、模型的复杂程度等。
2.特征选择常用的方法
按照特征子集的形成方式可以分为三种:完全搜索(Complete)、启发式搜索(heuristic)和随机搜索。
按照特征评价标准来分,根据评价函数与模型的关系,可以分为筛选式、封装式和嵌入式三种。
2.1 基于特征子集的形成方式的特征选择方法 基于特征子集的形成方式的特征选择方法主要有完全搜索(Complete)、启发式搜索(Heuristic)和随机搜索。
特征选择本质上是一个组合优化问题,求解组合优化问题最直接的方法就是搜索,理论上可以通过穷举法来搜索所有可能的特征组合,选择使得评价标准最优的特征子集作为最后的输出。如果我们有N个特征变量,则特征变量的状态集合中的元素个数就是$2^N$,通过穷举的方式进行求解的时间复杂度是指数级的 (O(2^{N} ))。
为了减少运算量,目前特征子集的搜索策略大都采用贪心算法(greedy algorithm),其核心思想是在每一步选择中,都采纳当前条件下最好的选择,从而获得组合优化问题的近似最优解。根据其实现的细节,又可将贪心算法分为三种:前向搜索 (forward search),后向搜索(backward search)和双向搜索 (bidirectional search)。
假定我们有一个特征集合${a_{1},a_{2},...,a_{d}}$,前向搜索的思想是:
第一步我们可以将每一个特征看成一个候选子集,例如依据给定的评价标准,特征${a_{1}}$的效果最优,则子集为${a_{1}}$,于是将${a_{1}}$做为第一轮的选定集;
第二步,则是往已有的子集中加入下一个效果最优的特征变量,例如对于子集${a_{1},a_{i}}$,当 i=2 时效果最优,则新的子集确定为${a_{1},a_{2}}$。如此重复进行搜索,直到新一轮获得的子集效果不如前一轮,则搜索停止。
后向搜索的做法,是以包含全部特征的集合开始,逐步剔除特征,直到找到效果最优的子集。双向搜索则把前向搜索和后向搜索结合起来,不断在选定的子集中加入新特征,并同时剔除旧特征。
因为采取的是贪心算法,它们仅考虑使本轮的子集最优,例如在第三轮假定选择$a_{5}$优于$a_{6}$,于是该轮的最优子集为${a_{1},a_{2},a_{5}}$,然后再第四轮中却可能是${a_{1},a_{2},a_{6},a_{8}}$比所有的${a_{1},a_{2},a_{5},a_{i}}$都更优。但是,若不进行穷举搜索,则这样的问题无法避免。
这三类算法在R语言的stats包和MASS包中的线性回归建模中都实现了。
2.2 基于评价准测的特征选择方法 按照特征评价标准来分,根据评价函数与模型的关系,可以分为筛选式、封装式和嵌入式三种。
2.2.1 过滤式(Filter) 通常把先进行特征选择,再进行建模的方法称为过滤式(filter),它主要侧重于单个特征跟目标变量的相关性,此时特征选择的标准和模型优化标准并不一定相同,和下一步将要使用的机器学习算法没有必然联系。
Dash和Liu把过滤式特征选择的评价标准分为四种,即关联度度量、距离度量、信息度量、以及一致性度量。
关联性度量:
距离度量:运用距离度量进行特征选择是基于这样的假设:好的特征子集应该使得属于同一类的样本距离尽可能小,属于不同类的样本之间的距离尽可能远。常用的距离度量(相似性度量)包括欧氏距离、标准化欧氏距离、马氏距离以及基于概率距离度量的KL散度等。
信息度量:信息度量是把信息论中基于熵的评估标准应用得到特征选择中,如信息增益(Information Gain)、信息增益率(Information Gain Ratio)、基尼指数(Gini Index)、WOE(Weight of Evidence)以及IV(Informationvalue)等。
一致性度量:试图找到与全集相同分类能力的最小特征子集。不一致性定义为如果两个样本在选定的特征子集上取值相同,却属于不同的类。
下面简单地介绍常见的评价函数:
(1) Pearson相关系数
Pearson相关系数的数学公式为:$r=\frac{cov(X,Y)}{\sqrt{var(X)var(Y)}}$
Pearson相关系数是最常用的判断特征和响应变量(response variable)之间的线性关系的标准。结果的取值区间为[-1,1],-1表示完全的负相关+1表示完全的正相关,0表示没有线性相关。
Python中,Scipy的 pearsonr 方法能够同时计算相关系数和p-value
1 2 3 4 5 import numpy as np from scipy.stats import pearsonr x = np.random.normal(0 , 1 , 100 )print pearsonr(x , x **2 )[0 ]-0.2072
在R中,用cor函数求相关系数
1 2 3 x <- rnorm(100 )cor(x ,x ^2 ) -0.132433
(2)信息增益(Information Gain)
假设存在离散变量Y,Y中的取值包括{y1,y2,…,ym} ,yi出现的概率为Pi。则Y的信息熵定义为:
信息熵有如下特性:若集合Y的元素分布越“纯”,则其信息熵越小;若Y分布越“混乱”,则其信息熵越大。在极端的情况下:若Y只能取一个值,即P1=1,则H(Y)取最小值0;反之若各种取值出现的概率都相等,即都是1/m,则H(Y)取最大值$log_{2}m$。
在附加条件另一个变量X,而且知道$X=x_{i}$后,Y的条件信息熵(Conditional Entropy)表示为:
(3)最大信息系数(Mutual information and maximal information coefficient,MIC)
Pearson相关系数不能反映变量之间的非线性关系;信息增益直接用于特征选择时通常变量需要先离散化,而且信息增益的结果对离散化的方式很敏感。但是最大信息系数克服了这两个问题。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。
MIC的性质:
对于所有无噪声并且非常数的函数关系,MIC的值都为1
对于两个有确定的函数关系的随机变量,不论这个函数关系是什么样的,MIC的值都是1
对于两个统计独立的随机变量MIC的值接近于0
Python中,minepy 提供了MIC功能。
反过头来看$y=x^2$这个例子,MIC算出来的互信息值为1(最大的取值)。
1 2 3 4 5 6 from minepy import MINE m = MINE() x = np.random.normal(0 ,1 ,100 )m.compute_score(x , x **2 ) print m.mic()1
R中minerva包的mine函数可直计算出mic的值。
1 2 3 4 library (minerva) x <- rnorm(100 ) mine (x,y=x^2 ) $MIC [1 ] 1
可以看出,虽然x与$y=x^2$是函数关系,Pearson相关系数却很相小,但是通过MIC为1可以发现二者之间强烈的非线性关系。
(4)距离相关系数 (Distance correlation)
距离相关系数是针对 Pearson 相关系数只能表征线性关系的缺点而提出的。其思想是分别构建特征变量和响应变量的欧氏距离矩阵,并由此计算特征变量和响应变量的距离相关系数。详细的定义和计算过程可参考维基百科。
距离相关系数能够同时捕捉变量之间的线性和非线性相关。当距离相关系数为 0,则可断言两个变量相互独立(Pearson 相关系数为 0 不代表变量相互独立)。其缺点是与 Pearson 相关系数相比,其所需的运算量较大,而且取值范围为 [0, 1],无法表征变量之间关联是正相关还是负相关。
R的 energy 包里提供了距离相关系数的实现
1 2 3 x <- rnorm(100 )dcor(x , x **2 ) 0.5880842
(5)WOE和IV
WOE是一种基于目标变量的自变量编码方式,信用评分卡模型中最常用这种编码方式。例如将模型目标标量为1记为违约用户,对于目标变量为0记为正常用户;则WOE(weight of Evidence)其实就是自变量取某个值的时候对违约比例的一种影响。
WOE的公式:$$woe_{i}=ln(\frac{p_{y=1}}{p_{y=0}})$$
IV的公式:$$IV_{i}=(p_{y=1}-p_{y=0})\times woe_{i}$$
那么, $$IV=\sum_{i=1}^{k}IV_{i}$$
例如下表:
变量(age)
bad(y=1人数)
good(y=0的人数)
woe
IV
0-18
10
50
log((10/40)/(50/100))
{(10/40)-(50/100)}log((10/40)/(50/100))
18-30
10
20
log((10/40)/(20/100))
{(10/40)-(20/100)}log((10/40)/(20/100))
30-50
20
30
log((20/40)/(30/100))
{(20/40)-(30/100)}log((20/40)/(30/100))
sum
40
100
表中以age年龄为某个自变量,由于年龄是连续型自变量,需要对其进行离散化处理,假设离散化分为3组,bad和good表示在这三组中违约用户和正常用户的数量分布,可以计算出每一组的WOE值和IV值,通过后面的公式可以看出,woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响。
该变量age的IV值为:
从公式来看的话,其实IV衡量的是某一个变量的信息量,相当于是自变量woe值的一个加权求和,其值的大小决定了自变量对于目标变量的影响程度
从另一个角度来看的话,IV公式与信息熵的公式极其相似。
变量的IV值表示着该变量对因变量的区分度,IV值越大,该变量的越有价值,从而可以用IV值来进行特征选择。
2.2.2 包裹式(Wrapper) 而把特征选择和模型优化的标准统一起来的方法则有包裹式(wrapper)和嵌入式(embedding)。包裹式的方法以模型的优化标准作为特征选择的标准,但仍然把特征选择和模型训练分为两个步骤。与过滤式特征选择不考虑后续学习器不同,包裹式特征选择直接把最终将要使用的学习器的性能作为特征子集的评价标准,比如准确率、召回率、AUC值、AIC 准则和 BIC 准则等评价标准。
赤池信息准则(Akaike information criterion, AIC)
贝叶斯信息准则(Bayesian Information Criterions, BIC)
其中k为参数数目,$L$是似然函数(likelihood function),n是数据中观测值的数量。
AIC 和 BIC 的表达式中均包含了模型复杂度惩罚项和最大似然函数项。不同的地方在于,在 BIC 的表达式中,惩罚项的权重随观测值的增加而增加。因此当观测值数量较大时,只有显著关联的特征变量才会被保留,从而降低模型的复杂性。
在建模时,我们可以通过最小化 AIC 或 BIC 来选择模型的最优参数。由表达式可以看出,AIC 和 BIC 倾向于复杂度低(越小越好)和符合先验假设(越大越好)的模型。在简单线性回归中,似然函数是依据残差服从正态分布的先验假设构建的,即如果特征变量的加入能够使残差更接近正态分布,则认为这个特征能够显著改善线性回归模型。
2.2.3 嵌入式(Embedded) 嵌入式则是把特征选择和模型训练融为一体,两者在同一个优化的过程中完成,不再分为两个步骤,即在学习器训练过程中自动的进行了特征选择。最典型的有L1正则化以及决策树算法,如ID3、C4.5和CART算法等,决策树算法在树增长过程的每个递归步都必须选择一个特征,将样本集划分成较小的子集,选择特征的依据通常是划分后子节点的纯度,划分后子节点越纯,则说明划分效果越好,可见决策树生成的过程也就是特征选择的过程。
(1) L1正则化
在优化理论中,正则化(regularization)是一类通过对解施加先验约束把不适定问题(ill-posed problem)转化为适定问题的常用技巧。例如,在线性回归模型中,当用最小二乘法估计线性回归的系数时,如果自变量存在共线性,系数的估计值将具有较大的方差,因而会影响后续参数的统计检验。如果在最小二乘法的参数估计表达式中添加L1正则项,则称为Lasso线性回归模型:
$$\widehat{\beta }=arg min_{\beta}[(Y-\beta X)^{T}(Y-\beta X)+\lambda|\beta|]$$
L1正则化将系数w的L1范数作为惩罚项加到损失函数上,由于正则项非零,这就迫使那些弱的特征所对应的系数变成0。因此L1正则化往往会使学到的模型很稀疏(系数w经常为0),这个特性使得L1正则化成为一种很好的特征选择方法。线性回归有Lasso回归,分类模型有L1逻辑回归。
(2) 基于树的模型
基于树的模型,如随机森林、GBDT、XGBOOST等都可以输出变量的重要度,从而达到特征选择的作用。
平均不纯度减少 (mean decrease impurity)
决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用基尼不纯度或者信息增益 ,对于回归问题,通常采用的是方差或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
平均精确率减少 (Mean decrease accuracy)
另一种常用的特征选择方法就是直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。
(3)递归特征消除 (Recursive feature elimination ,RFE)
递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征放到一边,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
RFE的稳定性很大程度上取决于在迭代的时候底层用哪种模型。例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的;假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
Python 的 scikit-learn 模块中提供了一种循环特征剔除 (recursive feature elimination, RFE) 的实现,遵循的也是后向搜索的思路。
3 代码演练
(1) 基于前向搜索、后向搜索和双向搜索的回归模型在R中的实现: 这三类算法在R语言的stats包和MASS包中的线性回归建模中都实现了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 library(MASS) initial <- glm(Class ~ tau + VEGF + E4 + IL_3, data = training, family = binomial) stepAIC(initial, direction = "both") Start: AIC=189.46 Class ~ tau + VEGF + E4 + IL_3 Df Deviance AIC - IL_3 1 179.69 187.69 E4 1 179.72 187.72 - VEGF 1 242.77 250.77 tau 1 288.61 296.61 Step: AIC=187.69 Class ~ tau + VEGF + E4 Df Deviance AIC - E4 1 179.84 185.84 + IL_3 1 179.46 189.46 - VEGF 1 248.30 254.30 tau 1 290.05 296.05 Step: AIC=185.84 Class ~ tau + VEGF Df Deviance AIC <none> 179.84 185.84 + E4 1 179.69 187.69 + IL_3 1 179.72 187.72 - VEGF 1 255.07 259.07 tau 1 300.69 304.69 Call: glm(formula = Class ~ tau + VEGF, family = binomial, data = training) Coefficients: (Intercept) tau VEGF 9.8075 -4.2779 0.9761 Degrees of Freedom: 266 Total (i.e. Null); 264 Residual Null Deviance: 313.3 Residual Deviance: 179.8 AIC: 185.8
基于AIC准则,通过双向搜索我们得到了最优的分类模型。
(2) 基于IV的特征变量选择在R中的实现: 在R中,smbinning包可以做变量的分箱、计算woe以及IV。用其自带数据集举例如下:
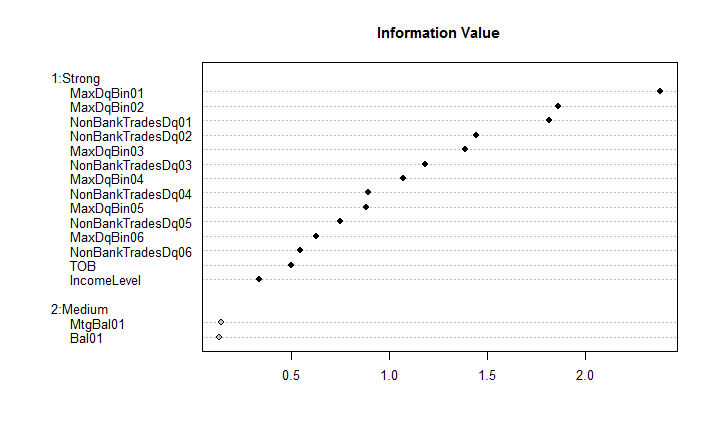
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 # Package loading and data exploration library(smbinning) # Load package and its data data(chileancredit) # Load smbinning sample dataset (Chilean Credit) str(chileancredit) # Quick description of the data 'data.frame' : 7702 obs. of 19 variables : $ CustomerId $ TOB $ IncomeLevel / 6 levels ,,,,..: 2 2 2 2 NA NA 1 2 1 1 ... $ Bal01 : num 605 1006 299 645 218 ... $ MaxDqBin01 : Factor w/ $ MaxDqBin02 / 8 levels ,,,,..: 1 1 1 1 1 1 1 1 1 1 ... $ MaxDqBin03 : Factor w/ $ MaxDqBin04 / 8 levels ,,,,..: 1 1 1 1 1 1 1 1 1 1 ... $ MaxDqBin05 : Factor w/ $ MaxDqBin06 / 8 levels ,,,,..: 1 1 1 1 1 1 1 1 1 1 ... $ MtgBal01 : num 0 0 0 0 0 0 0 0 0 0 ... $ NonBankTradesDq01: int 0 0 0 0 0 0 0 0 0 0 ... $ NonBankTradesDq02: int 0 0 0 0 0 0 0 0 0 0 ... $ NonBankTradesDq03: int 0 0 0 0 0 0 0 0 0 0 ... $ NonBankTradesDq04: int 0 0 0 0 0 0 0 1 0 0 ... $ NonBankTradesDq05: int 0 0 0 0 0 0 0 1 0 0 ... $ NonBankTradesDq06: int 0 0 0 0 0 0 0 1 0 0 ... $ FlagGB : int 1 1 1 1 1 1 1 1 1 1 ... $ FlagSample : int 1 1 1 1 1 1 1 1 1 1 ... table (chileancredit$FlagGB) # Tabulate target variable 0 1 636 5654 # Training and testing samples (Just some basic formality for Modeling) chileancredit.train=subset(chileancredit,FlagSample==1 ) chileancredit.test=subset(chileancredit,FlagSample==0 ) # Package application result=smbinning(df=chileancredit.train,y=,x=,p=0.05 ) # Run and save result result$ivtable # Tabulation and Information Value Cutpoint CntRec CntGood CntBad CntCumRec CntCumGood CntCumBad PctRec GoodRate 1 <= 17 1138 909 229 1138 909 229 0.2405 0.7988 2 <= 30 621 530 91 1759 1439 320 0.1312 0.8535 3 <= 63 1064 985 79 2823 2424 399 0.2249 0.9258 4 > 63 1427 1377 50 4250 3801 449 0.3016 0.9650 5 Missing 482 435 47 4732 4236 496 0.1019 0.9025 6 Total 4732 4236 496 NA NA NA 1.0000 0.8952 BadRate Odds LnOdds WoE IV 1 0.2012 3.9694 1.3786 -0.7662 0.1893 2 0.1465 5.8242 1.7620 -0.3828 0.0223 3 0.0742 12.4684 2.5232 0.3784 0.0277 4 0.0350 27.5400 3.3156 1.1708 0.2626 5 0.0975 9.2553 2.2252 0.0804 0.0006 6 0.1048 8.5403 2.1448 0.0000 0.5025 # Summary IV application sumivt=smbinning.sumiv(chileancredit.train,y=) sumivt # Display table with IV by characteristic Char IV Process 5 MaxDqBin01 2.3771 Factor binning OK6 MaxDqBin02 1.8599 Factor binning OK12 NonBankTradesDq01 1.8129 Numeric binning OK13 NonBankTradesDq02 1.4417 Numeric binning OK7 MaxDqBin03 1.3856 Factor binning OK14 NonBankTradesDq03 1.1819 Numeric binning OK8 MaxDqBin04 1.0729 Factor binning OK15 NonBankTradesDq04 0.8948 Numeric binning OK9 MaxDqBin05 0.8844 Factor binning OK16 NonBankTradesDq05 0.7511 Numeric binning OK10 MaxDqBin06 0.6302 Factor binning OK17 NonBankTradesDq06 0.5501 Numeric binning OK2 TOB 0.5025 Numeric binning OK3 IncomeLevel 0.3380 Factor binning OK11 MtgBal01 0.1452 Numeric binning OK4 Bal01 0.1379 Numeric binning OK1 CustomerId NA Not numeric nor factor18 FlagSample NA Uniques values of x < 10 # Plotting smbinning.sumiv smbinning.sumiv.plot(sumivt,cex=0.8 ) # Plot IV summary table
通过IV的大小进行特征排序,从而达到特征选择的目的。
(3) 基于L1正则化的特征变选择在R中的实现: R语言中glmnet包可以实现L1正则化、L2正则化的分类与回归模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 library(glmnet) library(ISLR) Hitters=na.omit(Hitters) x=model.matrix (Salary~.,data=Hitters)[,-1 ] y=Hitters$Salary grid =10 ^seq(10 ,-2 ,length =100 )lasso.model=glmnet(x,y,alpha=1 ,lambda =grid ) #交叉验证,选择最优的lambda cv .out=cv .glmnet(x,y,alpha=1 ,lambda =grid )bestlam=cv .out$lambda .min lasso.model2=glmnet(x,y,alpha=1 ,lambda =bestlam) coef(lasso.model2) 20 x 1 sparse Matrix of class "dgCMatrix" s0 (Intercept) 24.6396990 AtBat . Hits 1.8499834 HmRun . Runs . RBI . Walks 2.1959762 Years . CAtBat . CHits . CHmRun . CRuns 0.2058514 CRBI 0.4095910 CWalks . LeagueN . DivisionW -99.9733911 PutOuts 0.2158910 Assists . Errors . NewLeagueN .
通过这个实验可以看出,lasso的系数结果是稀疏的,19个预测变量中13个的系数为0。即使用交叉验证选择$\lambda$值建立的lasso模型仅包含6个预测变量。
(4) 基于树模型的特征选择在R中的实现: 在R语言中,基于树的模型,如随机森林、GBDT、XGBOOST等都可以输出变量的重要度,以随机森林为例。
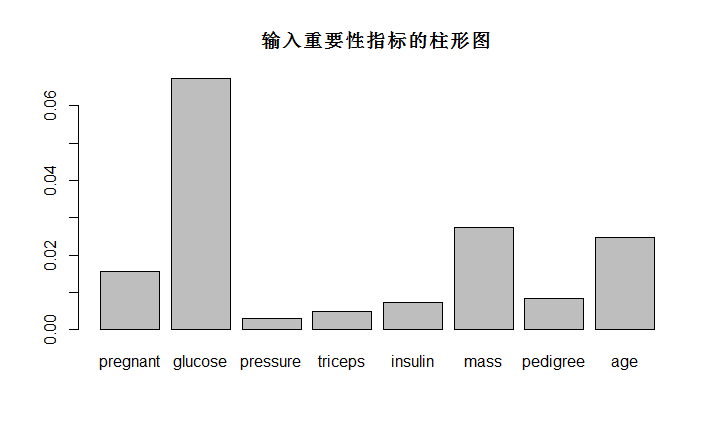
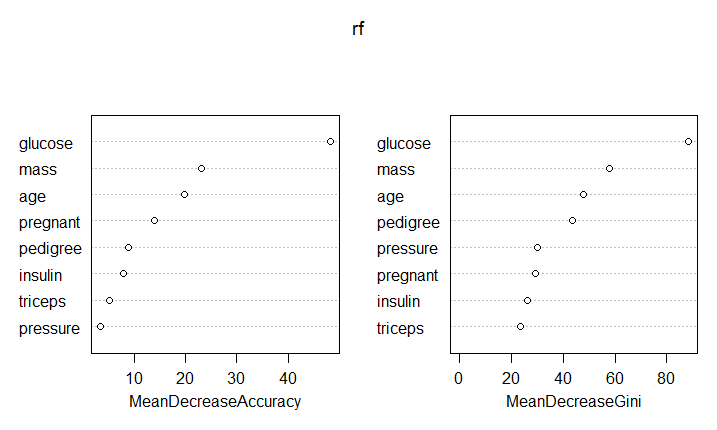
1 2 3 4 5 6 7 8 9 library(randomForest ) library(mlbench ) # load the data data(PimaIndiansDiabetes ) rf <- randomForest(x=PimaIndiansDiabetes [,1 :8 ], y=PimaIndiansDiabetes[,9 ],importance = T,ntree=500) barplot(rf $importance[,3 ],main="输入重要性指标的柱形图" ) varImpPlot(rf ,sort=TRUE,n.var=nrow(rf $importance))
随机森林是基于决策树的集成模型,通过上图,我们可以很清楚地发现重要的特征。
### (5)基于递归特征消除法的特征选择在R中的实现:
在R中,caret包可以使用递归特征消除法,主要使用rfe函数。
rfe参数说明:
x,预测变量的矩阵或数据框
y,输出结果向量(数值型或因子型)
sizes,用于测试的特定子集大小的整型向量
rfeControl,用于指定预测模型和方法的一系列选项
一些列函数可以用于rfeControl$functions,包括:线性回归(lmFuncs),随机森林(rfFuncs),朴素贝叶斯(nbFuncs),bagged trees(treebagFuncs)和可以用于caret的train函数的函数(caretFuncs)。
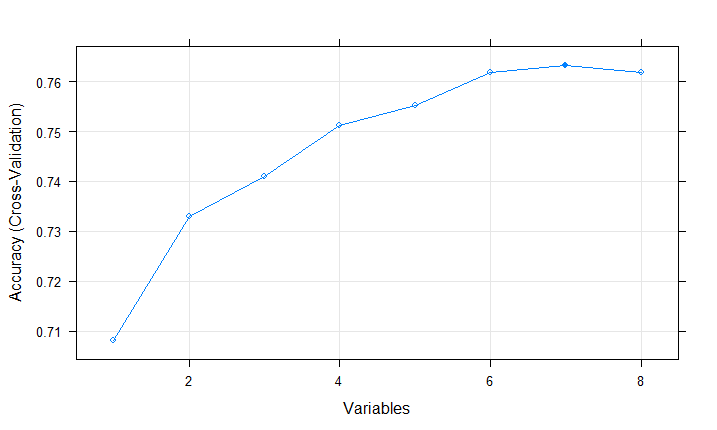
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #ensure the results are repeatable set .seed(7) #load library(mlbench) library(caret) # load data(PimaIndiansDiabetes) #define control # run results PimaIndiansDiabetes[,9], sizes=c(1:8), rfeControl=control,metric #summarize print(results) Recursive Outer Resampling Variables 1 0.7082 0.3030 0.04902 0.1181 2 0.7330 0.3920 0.06703 0.1564 3 0.7409 0.4115 0.06525 0.1582 4 0.7512 0.4409 0.06988 0.1691 5 0.7553 0.4452 0.07909 0.1911 6 0.7618 0.4583 0.08094 0.1897 7 0.7631 0.4620 0.08448 0.1927 * 8 0.7617 0.4615 0.07810 0.1789 The glucose, mass, age, pregnant, pedigree #list predictors(results) [1] "glucose" "mass" "age" "pregnant" "pedigree" "insulin" "triceps" #plot plot(results, type=c("g" , "o" ))
从案例中可以看出,通过递归特征消除,发现用所有变量中的某7个自变量的模型是最好的,并且找出了最重要的5个特征。
4 结束语
特征工程是门艺术,也是每一个数据科学家的必修课,因此每个数据科学家既应该像一个统计学家和工程师,又应该像一个艺术家。
参考文献
[1] Dash M, Liu H. Feature selection for classification[J]. Intelligent data analysis, 1997, 1(3): 131-156.
[2]http://blog.datadive.net/selecting-good-features-part-i-univariate-selection/
[3]http://blog.datadive.net/selecting-good-features-part-ii-linear-models-and-regularization/
[4]http://blog.datadive.net/selecting-good-features-part-iii-random-forests/
[5]http://blog.datadive.net/selecting-good-features-part-iv-stability-selection-rfe-and-everything-side-by-side/
[6]http://scikit-learn.org/stable/modules/feature_selection.html#univariate-feature-selection
[7]http://blog.csdn.net/qtlyx/article/details/50780400
[8]http://minepy.readthedocs.io/en/latest/
[9]https://cran.r-project.org/web/packages/minerva/minerva.pdf
[10]http://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
[11]http://www.analyticsvidhya.com/blog/2016/03/select-important-variables-boruta-package/
[12]https://www.zhihu.com/question/28641663
[13]https://cran.r-project.org/web/packages/smbinning/smbinning.pdf
[14]http://www.scoringmodeling.com/rpackage/smbinning/
[15]蒋杭进. 最大信息系数及其在脑网络分析中的应用[D]. 中国科学院研究生院 (武汉物理与数学研究所), 2013.